
The State of AI, Part 2: Expert Systems, Intelligent Gaming and Databases, Virtual Personal Assistants
The State of AI: Expert Systems, Intelligent Gaming
and Databases, Virtual Personal Assistants
Siri cant play Jeopardy!, and Watson cant take dictation. Watson cant talk to Siri
The state of artificial intelligence,
cognitive systems and consumer AI. Part II
Author: Susanne Lomatch
Expert systems were among the first major applications of AI. The appeal of producing a system that could emulate the knowledge, diagnosis, planning and decision-making capability of a human expert has driven advances in machine learning, natural language processing (NLP) and knowledge engineering (namely knowledge representations or ontologies used in knowledge management and reasoning) that have made large-scale expert systems like IBMs Watson a possibility. Watson, a DeepQA descendant of Deep Blue (whose chess-playing prowess scored it a win against Garry Kasparov in 1997), showed its question-answer (QA) expertise by winning a Jeopardy! tournament in early 2011.
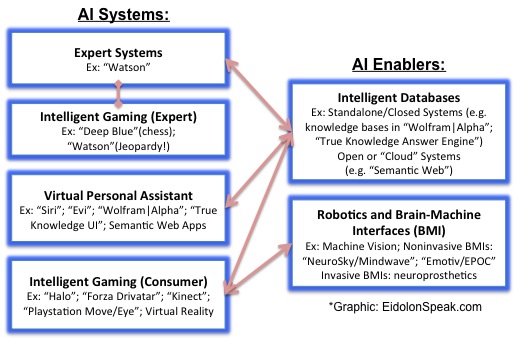
Advances that have enabled large-scale expert systems are now beginning to permeate into consumer devices, from virtual personal assistants (VPAs) on mobile devices that emphasize automatic speech recognition (ASR) and basic task learning and planning capabilities (e.g. Siri), to intelligent gaming systems and devices that monitor gamer movements and interface the gamer more optimally to the gaming system (e.g. Kinect, PlayStation Move/PlayStation Eye motion controllers). Gamers are already embracing machine vision devices that detect body motion and eye movement as an integral part of the gaming experience, and with brain-machine interface (BMI) technologies moving from science fiction to a possible reality, we can imagine actual human perception and thought fusion into virtual reality games (more on the infancy of BMIs in Part 4 of this series).
Intelligent databases that organize and manage information to a degree that enables AI systems (and humans) to better exploit the relevant information needed are a reality as standalone (closed) systems (e.g., the knowledge bases in Wolfram|Alpha, True Knowledge Answer Engine), and are now permeating open and scalable (networked or cloud) information systems. The World Wide Web may yet morph into a giant relational database that can learn, driven by a semantic structure and an ontological, dynamically linked architecture (e.g. the Semantic Web).
Links to specific reviews in Part 2, located in this document:
Watson
Siri / Trap!t / DARPA PAL / DARPA CALO (and newer rivals)
True Knowledge Answer Engine
Semantic Web (Infrastructure and Apps)
I also suggest three primers Ive put together on AI elements that are key to the systems reviewed. Links to these primers:
Primer on Knowledge Representations & Acquisition
Primer on Natural Language Processing
(Disclaimer: The reviews in
this article are meant to inform and entertain, and contain a healthy dose of
critical appraisal. I encourage readers who find factual errors, or who have
alternative intelligent appraisals and opinions, to contact me (contact link below). I will include any substantial
feedback on the dialogue site area dedicated to AI (Click
HERE for link to the AI dialogue area). I also welcome constructive and friendly
comments, suggestions and dialogue.)
Watson
Classification: Expert System
As per IBMs own
description: Watson is a highly
advanced Question Answering system
built on IBMs DeepQA
technology for hypothesis generation, massive evidence gathering, analysis, and
scoring
an application of advanced Natural Language Processing, Information
Retrieval, Knowledge Representation and Reasoning, and Machine Learning
technologies to the field of open-domain question answering
the computing
system will be able to understand complex questions and answer with enough
precision, confidence, and speed to compete on Jeopardy!
Indeed, in early 2011, Watson competed against Jeopardy!s finest, and won. Here are some caveats to this accomplishment:
Watson fills an air-conditioned room and is the collective size of approximately 10 refrigerators (10 racks of 90 IBM POWER 750 servers running Linux, 15 terabytes of RAM, 2880 processor cores operating at 80 teraflops).
Specific to the Jeopardy! game: precision vs. % answered in terms of human cloud performance shows top Jeopardy! players are on the tail of the distribution curve, with their median in the 65-70% range @80-100% precision vs. 40-50% @75-100% precision for the average player. The Watson prototype systems [1,2] showed a power law decline in terms of precision at low % answered (high confidence) vs. higher % answered (low confidence), with confidence being a degree of freedom or risk parameter in the optimization space. What this says to me is that their optimization - if thats what it is – holds a dependence between % answered and confidence level, and the confidence level goes down with more questions answered. Is this evidence of an unwieldy large-scale (LS) optimization problem that IBM tweaked before competing live on Jeopardy! in early 2011?
Does Watson engage in LS optimization to find a ranking of high precision answers in terms of confidence levels, and then report the answer with the highest score(s)? I dont think humans do it this way – humans store the learned answer somewhere and recall it, and that recall is based on pattern recognition, association and other recall-related processing in the human brain.
The most impressive piece of Watsons accomplishment is the natural language processing (NLP) capability, in recognizing the communicated information. (See how Watson uses NLP, reviewed in the NLP primer below.) However, processing that information to get an answer appears to be mostly brute force LS optimization, not novel storage and retrieval ala human neural processing. The size of Watson underscores that approach – and as such, we are left wondering whether there is a better approach at producing an artificially intelligent Jeopardy! competitor.
As indicated in [2], broad-domain relation detection in terms of goal-directed information extraction is a major open area of research. (Watsons current ability to effectively use curated databases to simply look up the answers is limited to fewer than 2 percent of the clues. Watsons use of existing databases depends on the ability to analyze the question and detect the relations covered by the databases. In Jeopardy the broad domain makes it difficult to identify the most lucrative relations to detect.)
Watson deserves some credit for employing multiple levels of training in game strategy models specific to Jeopardy! Training and learning (including on the job training and learning, though its not clear how much Watson does that during a real game) are key components to any AI system with evolutionary capability.
IBM says that Watson and DeepQA will be adapted and marketed toward business and government applications that include Customer Relationship Management, Regulatory Compliance, Contact Centers, Help Desks, Web Self-Service, Intelligence, etc. It is not clear to me what in Watson can be translated toward a consumer-driven AI application. This may be a harsh conclusion, and I invite readers who have an alternate view to write a rebuttal on this and I will publish it.
Finally, Watson is a specialized expert AI system that has impressive capability, but I agree with John Searle, it cannot think [3].
Siri / Trap!t
/ DARPA PAL / DARPA CALO (and newer rivals)
Classification: Virtual Personal Assistant
Siri is an intelligent personal assistant application for the Apple iOS, the operating system for the iPhone. According to Apple, Siri incorporates natural speech processing to recognize a users voice and commands; it also learns a users preferences and requested actions over time to complete user tasks, such as making calls, finding directions, searching the internet or scheduling meetings, interoperating with other iOS apps to accomplish tasks.
Siri the app is an offshoot of technology developed by SRI Internationals Artificial Intelligence Center, funded in part though several Defense Advanced Research Projects Agency (DARPA) programs, namely the Personalized Assistant that Learns (PAL) and the Cognitive Assistant that Learns and Organizes (CALO) programs. Siri the company was a venture spinoff of SRI, developing the iOS/iPhone app between 2007-2010. In early 2010, Apple acquired Siri, and made it exclusively available on the iPhone (there were plans to make it available on other phone platforms, namely Android devices). Industry sources claim that Apples Siri implementation also uses intellectual property licensed from Nuance Communications, which makes the automatic speech recognition (ASR) software Dragon NaturallySpeaking.
Recent reviewers tout Siri as the most accurate of voice recognition apps available for phone devices, and the functionality also superior – likely due to the effective interoperability with other built-in iOS apps. Reviewers also note that Siri handles user context well, in terms of recognizing what task a user really wants – an example is Tell Ted his hair looks amazing today – Siri will recognize that the user wants to send Ted a message about his hair.
So what in Siri is AI? Clearly the NLP and machine learning capabilities, to the extent that Siri implements them. (See how Siri uses NLP, reviewed in the NLP primer below.) As pointed out by more critical reviewers [4], Siri is likely hard-coded with chatterbot-style input/output pairs, meaning the user can voice a commonly-used phrase or set of terms and Siri will respond by incorporating hard-coded relevancies, some quite amusing. The point is made though that unlike chatterbots that are closed coded, Siri has access to the cloud, the internet, and as such has the potential to learn new I/O pairs or responses, and tasks. Siri also has temporal awareness in executing tasks. This adaptability and evolutionary capability, especially personalized to the user, brings AI to Siri. Except Siri is still weak AI. It cannot think.
As one commenter stated in the above article: We've tried this since the sixties. All serious AI researchers have given up on large databases of canned responses as a solution to the AI problem. It is merely a curiosity, like sophisticated chess programs. But there is no consciousness [strong AI] behind it.
Not to be too critical though, Siri brings NLP and multitasked functionality based on trained/learned interpretation of user responses to the masses, and thats a good start on the road to developing a highly functional AI consumer companion. When (or if) it will pass a Turing Test is quite another matter.
The DARPA PAL/CALO programs generated a multitude of machine learning and reasoning technologies, including NLP algorithms that were adapted to Siri. Some of this framework is available to researchers through the SRI AIC, including software components, documentation and publications.
What other cool technology did DARPA PAL/CALO spawn? A personal assistant that exceeds Siris capabilities for military field use? PAL after all was a DARPA/DoD program, and the goal of any DARPA program is to produce practical technology for military use, first and foremost. Perhaps well see a spinoff of more advanced but classified PAL-inspired technology at some point?
Trap!t is another technology offshoot of PAL/CALO – it is a web scraper that assists a user in intelligent information extraction from the web. Trap!t is available as a browser application, much like a search engine. According to the website (http://trap.it/) Trap!t is powered by advanced AI learns your tastes and continues to deliver on topic content, even as your tastes evolve works 24/7 capturing what you want Now the web follows you. Trap!t sounds like it has some commonality with Semantic Web efforts (see below), which aim to make sense out of web information through smart data representation and dynamic linking. The difference is that Trap!t mines information from the existing web infrastructure using web bot actions and filtering after learning user preferences. Some reviewers call Trap!t an AI-powered aggregator. Others called it a heuristic metablog-zine and a content concierge. Most of the reviewers thought it did not replace a Google search with smartly chosen keywords at finding relevant information.
So how much AI is in Trap!t? It aggregates information based on user preferences, employing contextual processing (keyword matching against content with the same context, making associations at a deeper level than text), but is it just post-processing the information found by running it through a filter, albeit perhaps a smart, adaptable one? The developers need to establish that this engine isnt just another flavor of search engine optimization (SEO). As for Trap!t being the Siri sibling, its lack of NLP skills ala voice recognition integrated with adaptable multitasked interoperability makes it a dim sibling. The developers ought to think about how to make Trap!t a solid NLP-based interface to Semantic Web applications, in the event that the web does evolve in the Semantic Web/Web 3.0 infrastructure direction (more on that below).
Trap!t isnt unique – there are several similar efforts, namely Thoora and StumbleUpon, which advertise that they employ adaptable filtering to web scrape to a users preferences and Webglimpse, site search software that includes a web administration interface, remote link spider, and the powerful Glimpse file indexing and query system.
At the end of 2010, Google executives claimed that the next big thing for them was contextual discovery search, pushing information to people based on their location and personal preferences, so we may likely see something in this realm from Google soon, especially on mobile devices. Readers should keep in mind though that Google search algorithms contain AI [5], in particular, those derived from machine learning and translation, and NLP, and as of March 15, 2012, Goggle announced plans to release semantic search capability for its engine.
Google is also playing catch-up with Apple in the VPA space, rumored to soon release Majel, a rival mobile application system to Siri, and named after Star Treks Majel Barrett-Roddenberry, the effervescent voice of the Enterprise (readers can refresh and amuse themselves by watching this video). Majel will presumably build upon Google Voice Search.
True Knowledge has just released Evi, a Siri rival that runs on both the iPhone/iOS and Android mobile platforms. Evi is a cloud-based AI engine that builds upon True Knowledges core semantic search technology. Evi is also being marketed as a mobile question-answer engine, based on the True Knowledge Answer Engine, reviewed in greater detail below. In that sense, Evi uses ASR for speech-to-text and then interfaces to TKs QA knowledge base to provide an answer, but it also purportedly checks other sites to see if the question has been answered. (Interestingly, there is a charge for the use of Evi on an iPhone, reportedly to cover the cost of the ASR service provided by Nuance, but the app is free on Android OS-based systems that perhaps dont use Nuance.) How much NLP is done locally within the Evi app vs. remotely on TKs servers? Is Evi just a smart user interface to TKs ecosystem?
Initial reviews of Evi are mixed. In terms of answering questions, Evi excels over Siri, giving relevant answers somewhat like an abbreviated Wolfram|Alpha, whereas Siri stalls and asks whether to search the web (the example questions were how do I make apple pie (Evi returns a list of recipes) and who was president when Queen Elizabeth II was born (Calvin Coolidge)). Other testers found Evis NLP abilities lacking in terms of correctly interpreting certain questions (how much does a Panda weigh got translated as way). On the negative side, Evi does not interface to other applications for multitasking nor does it have Siris learning capability for multitasking, and even when/if it does, Siris integration into the iPhone/iOS may give it an edge.
Finally, NovaSearch is a phonetic search engine based on phonetic speech recognition, a very different paradigm from speech-to-text search employed in Siri or Google Voice Search, or even from the higher-level paradigm of semantic search (as in Evi/TK and Semantic Web apps). NovaSearch decodes phonetic sounds (phonemes) into a stream of phonetic symbols, producing a shortlist of likely matches, and then uses a process called acoustic rescoring to refine the results via more detailed modeling. In doing so it can skip text processing/recognition steps and use phonetic symbols rather than words to search, for example, entire addresses in one process instead of matching each line, working backwards from the country or city to the house number. This phonetic recognition approach is faster and requires lower processing power, and can be embedded and operated locally on the mobile device, sending a lot less data for search (presumably a remote custom database is used to then translate the symbols for further search as necessary). Though limited, this approach may be interoperated with normal speech-to-text approaches to cut down on bandwidth requirements and improve speed. Both Siri and Evi likely push much of the ASR/NLP processing to a remote server, feeding final, annotated results back to the local mobile client, but in doing so transmit considerable data bandwidth.
Wolfram|Alpha
Classification: Virtual Personal Assistant and AI Enabler (Intelligent Database)
Wolfram|Alpha is a question-answering (QA) engine that answers factual queries directly by computing the answer from structured data, rather than providing a list of documents or web page links that might contain the answer, as a search engine might. W|A computes answers from a knowledge base of curated, structured data, whereas a standard search engine indexes a large number of answers and then applies filters and rankers to provide an answer list.
Stephen Wolfram insists that W|A is not a semantic search engine, which analyzes user input intent and the contextual meaning of terms as they appear in the searchable dataspace (in W|As case, its proprietary knowledge base of curated, structured data). Wolfram instead calls W|A a platonic search engine, unearthing eternal truths that may never have been written down before [6].
In reality, W|A certainly appears to figure out what a users question means (looking at semantics, objective and subjective information in the question), and then computes an answer from interpreted meaning and query information, using W|As knowledge base in the process. In that sense, W|A is still a type of semantic search, but it inserts a computational knowledge step that operates on interpreted query meaning to find an answer (the more factual and objective the meaning, the better, as I discuss in examples below), instead of directly indexing to a semantically-matched question answer. This architecture ties to Wolframs view that everything is computable from simple rules and principles.
W|A operates much like Mathematica in processing symbolic math queries (Example: derivative log(x)/x yields the expected answer, complete with plots, alternate forms, integrals, limits, etc.), but it is extended to process natural language queries and utilize multiple database and web sources to present a calculated answer. Example: What are the top ten countries by land mass? W|A interprets land mass as total area/land area and taps its own structured database to return the information, very quickly, with a nice structured table format, including land area estimates.
W|A doesnt handle questions that might lack complete information or expected phraseology well, though. Example: What is the most expensive gemstone? returns a page of stats that suggest W|As inability to interpret the question, from any contextual level (it focuses on expensive as the input interpretation and never recovers from there). There doesnt appear to be a way for the outside user to train W|A how to interpret the question and provide an acceptable range of answers. W|As grasp of expensive may be severely limited, whereas to the casual user expensive would have a relevant meaning in terms of cost of goods by some set of tangible measures. A human might answer this question stating, By carat weight, the most expensive gemstone in US dollar terms is a IF-grade Burmese ruby. A human answer might contain some mixture of fact and subjectivity, as much so as the original question.
W|A then is designed to respond to factual-based questions that are properly phrased, meaning the phraseology is contextually interpretable by W|As limited ability in NLP. In that sense, it would be interesting if W|A could learn through a dialog when it first fails at even the simplest interpretation. But then W|A might be open to misguided training if it were trained by a user with faulty information, in short, a bad teacher. As a measure against this, W|A could be trained to handle subjective information and learning, without the pitfall of learning false or misleading information. W|A does provide a user feedback entry at the bottom of an answer page, so perhaps this is the way for a user to communicate deficiencies. (The reader may note that Google search catalogues a recognizable keyword most expensive gemstone as the most popular, and returns a list containing relevant, useful links based on its broad database and what links it has determined the user has previously searched.)
It would be interesting to see how Watson would handle the most expensive gemstone query.
Finally, W|A has been described as containing a common sense inference engine much like Cyc, an old AI project that assembled a comprehensive ontology and knowledge base of everyday common sense knowledge, with the goal of enabling AI applications to perform human-like reasoning. OpenCyc is an open-source version of Cyc, including the entire Cyc ontology containing hundreds of thousands of terms, along with millions of assertions relating the terms to each other (these are mainly taxonomic assertions, not the complex rules available in Cyc). Perhaps W|A builds on this open source in its implementation. The parallels to the Semantic Web infrastructure and apps are evident (see below).
The difference is that unlike the Semantic Web, W|A is not open and scalable in the true sense of the internet – its knowledge database is closed and available only through the application programming interfaces (APIs) that W|A contains, which also link to a computational engine, including Mathematica. Perhaps Stephen Wolfram wants it that way – i.e., his knowledge base will grow with what he determines to be the eternal truths.
True Knowledge Answer
Engine
Classification: Virtual Personal Assistant and AI Enabler (Intelligent Database)
The True Knowledge Answer Engine (TK|AE) is a proprietary question-answering (QA) engine and knowledge base that uses TKs semantic-based architecture and search capability.
TK|AE gives answers that are similar to W|A (as evidenced recently via the Evi mobile app, which is a user interface link to TK|AEs ecosystem and knowledge base). How do the two differ? TK|AEs query/answer system, knowledge generator and base are likely similar enough to those of W|A. TK|AEs knowledge generator sounds like the knowledge inference engine that W|A might use, drawing upon knowledge base facts, other generated facts or external feeds of knowledge to deliver an answer. TK|AEs NLP interface and algorithms likely look at the semantic content and information in the query, translating the question into the TK query language. TK|AE emphasizes that its NLP is optimized to disambiguate ambiguous questions, including interpretations of questions that are unlikely. How well TK|AE does this vs. W|A ought to be systematically tested. (I havent yet seen such a test, i.e., something more than just a few anecdotal comparisons, to properly gauge semantic prowess.)
The major difference between TK|AE and W|A is likely in the computational knowledge realm. W|A has a CK engine that includes Mathematica and its own proprietary brand of modeling, symbolizing, encoding and calculating answers to NLP-translated factual queries. TK|AE responded to the derivative log(x)/x with a statement, Sorry, we don't yet have an answer to that question.
The other difference is that W|A is more of a closed system, if one is to believe what TK says on their website: The Knowledge Base grows through Knowledge Addition, either from users via the browser interface, or imported in volume from Other Sources. A key design decision is that all components are extendable by users. In addition to users adding facts, they can also extend the questions that can be translated into whole new areas and even provide new inference rules (and even executable code for steps that involve calculation) for the Knowledge Generator.
If TK|AE is more open and scalable, it might be a prime test bed for the Semantic Web.
How did TK|AE handle the What is the most expensive gemstone question? Much better than W|A: it returned the answer The most expensive gem is the red diamond. It sells for over one million dollars per carat! with a link to the source page and a chance to click on a list of more answers.
Semantic Web
(Infrastructure and Apps)
Classification: AI Enabler and Virtual Personal Assistant
The Semantic Web is an innovative paradigm that encompasses defining information and services on the web semantically, such that web tools can more intelligently interpret or comprehend web user requests and so that machines can process web data more efficiently [7,8]. In the current Web 2.0 state, the power of the web is limited structurally to a static system, where data types are generally blind, and data context, or a semantic interpretation of the data, is not exploited.
Further, dynamically linked variables often found in object-oriented programming languages remains elusive to what the web could revolve into – a giant relational database, where the power of data relationships can be leveraged to provide web users with a significant advantage in finding and using just the data/information theyve been looking for, and not a mountain of data/information that is irrelevant or that they dont need [9].
The Web 3.0 standard would begin to incorporate semantic formats for data and links, among other improvements, such as more intelligent search capability and personalization aspects for both users and information providers. Integrating fully dynamically linked data structures for links and information is likely an evolution beyond Web 3.0 though, as that realization requires a major overhaul of the web infrastructure, as we currently know it.
Some pessimists have called the Semantic Web an unrealizable abstraction that would return the web to the realm of experts and authorities. Let me answer that prejudicial criticism by stating that the vision is to move such infrastructure innovations into the background, and to create smart, AI-based tools for users and information providers that exploit the new infrastructure. Just as wireless providers upgrade their networks to include new standards and capabilities, and to support new devices and tools, so too can the web. To believe that we will remain ad infinitum with the current static structure is unreasonable. Of course, there are those that may believe that existing tools can be improved or new ones devised to mine the current static system to deliver more intelligent capability, but that limited, static thinking would never have moved us from the direct current to the alternating current or from the wired to the wireless.
Even a few highly educated pessimists have weighed in with unproductive, self-serving criticisms [6]: The problem with the Semantic Web is that the people who post the content are expected to apply the tags, remarks [Stephen] Wolfram. And the tagging system involves a complicated categorization of all the things that might exist—what philosophers call an ontology. Like any comprehensive world-system, the Semantic Web ontology is subject to endless revision, with many gray areas. For instance if theres a cell phone antenna on a bridge girder, is the structure a bridge or a cell phone tower? Its proved easier for us to hand-curate the existing data that we find in books and on the web. This is feasible because a lot of the data were interested in is purely scientific — things like the chemical formula of some compound. As this kind of data isnt being constantly revised, its possible to stay ahead of the curve.
Not all of the information that ever existed can be hand-curated – much can be automatically curated and structured via machine learning tools applied to both labeled and unlabeled data/information, with emphasis on semantic content and a proper way to handle any ambiguities through inferencing, etc. Perhaps Wolfram fancies the idea of having his own knowledge base of eternal truths, whereupon he defines and controls what is catalogued and retrieved ( the New Kind of Science notion that everything is computable gave me the confidence to go ahead with Wolfram|Alpha...Pretty much every branch of knowledge that weve coded up has an expert in the chain, he says. Its important to include what you might call guild secrets—tricks or rules of thumb that practicing experts use. Some of these things arent in books and arent well-known. [6]). My question to Wolframs Semantic Web criticism is: how then does one deal with abstractions in the data/content that may be highly useful, but that cannot be easily integrated into his models or computational algorithms (or known models and algorithms)? Will the information be discarded, since his models and algorithms cannot catalogue it properly? How does one handle the construction of a complete and consistent set of axioms for recursively enumerable theories (Gödels Incompleteness Theorem)? Ill admit Id pay to see a debate between Wolfram and Tim Berners-Lee (co-founder of the Semantic Web concept).
The Semantic Web has been in the development stage in terms of standards and tools for some time [8], much of it open source. For data encoding, a resource description framework (RDF) structure is proposed, whereby uniform resource identifiers (URIs), such as typical HTTP uniform resource locator (URL) addresses we all use, contain syntax statements that have or point to content descriptions and also point to other URIs. In a data model form, the syntax is subject-predicate-object, where the subject is a resource (e.g. a URI), and the predicate represents features of the resource and also relates the subject to the object. This is referred to as a triple. In graphical form, the URIs are nodes that have properties, and are linked to other nodes that have related properties and values. As an example, a website on the sun could contain temperature data that includes links to other websites with solar temperature data. Formal RDF would codify this into a knowledge representation so that it is processable and meaningful. It has a possibility of going beyond traditional relational database models, particularly if ontologies are included and, as I mention above, data links are dynamic [9]. Ontologies can interpret the meaning of a particular data set, and more generally they can provide an extensive taxonomy (definitions of all kinds of data objects and the relationships between them, even across different platforms) and inference rules (e.g., an if-then-else relationship between variables).
The challenge with ontologies is maximizing their value so that they are applicable to a wide range of uses, are re-usable, and are merge-capable with other ontologies to further increase value. Ontology mapping is key to the concept of association in intelligent systems. Think of a learning system – we start with one way to learn (one ontology) and then merge that with another way to learn (another ontology) and we end up with a more powerful learning capability (the collection of ontologies). This may be simplified given that learning systems are more complex than a typical ontology, but what is conveyed here is that ontologies are necessary components of a Semantic Web in which learning capability might exist.
The W3C community [8] has developed a web ontology language (OWL) for ontology construction incorporating RDF syntax, query tools that are optimized for RDF such as SPARQL, browsers, search engines, a Semantic Web compliant Wikipedia called DBpedia, and a large collaborative knowledge base consisting of semantic metadata called Freebase. A list of tool development efforts can be found HERE. The community is a combination of private and public institutions that contribute to the ongoing effort to realize the power of the Semantic Web paradigm, with the intent that when the standards and tools become sophisticated and user-friendly, the rest of the world might begin to test and use a platform that would form the basis of the new infrastructure. Think back to the advent of HTML-based browsers such as Netscape Navigator and the excitement that was generated when casual users began to drive it for the first time.
What could a Semantic Web do that has AI designers so excited?
On a broad scale it is the idea that the web would have the capability to learn and to evolve in an intelligent direction, so as to better serve users, developers and information providers. The existence of ontological structure - which is so central to natural language, learning, knowledge representation, pattern recognition and information association and recall – is key. In the Semantic Web space, data encoding and link structure has the potential to be dynamic, leading to the built-in capability of ontology mapping, where ontologies are strengthened, reused and linked with other such ontologies to grow a knowledge base, or as I like to put it, a collective memory. The motivation for this model is to more closely match a system like that of the human brain, which is a neural network of synaptic circuits that represent a collective memory that can learn and think (thats putting it simply!). Synapses have strengths that are dynamic and the brain is a highly interconnected system (ultra high integration density) of these local memory circuits. A single neuron cell can contain several thousand synapses. Though there are cells, layers and regions, the brain has built-in redundancy, another feature to consider for the Semantic Web future, as a prevention of information loss: making links truly dynamic but not lead to information loss (a real downside threat). Cloud computing incorporates dynamically scalable architecture concepts (scale-out databases, autonomic computing, reliability, etc.) that will undoubtedly be important for the growth of the Semantic Web in its dynamic form [9].
Software developers arent waiting for the advent of Web 3.0 and the Semantic Web to develop specialized applications that adopt ontological structure and machine learning to achieve built-in AI capability in processing and recognizing information. (Note I avoid the oft-misused term understanding information, which has a connotation of human cognition to it.) One such product is Topic-Mapper from ai-one. This product creates adaptive ontologies from information with no human maintenance or intervention, and generates dynamic topologies that transform data structures allowing for incremental learning. Ai-one claims that its Topic-Mapper can be used to turn search engines into more accurate answer engines that deliver more precise answers (watch out Wolfram|Alpha!), and calls Topic-Mapper a core programming technology. One independent developer is using Topic-Mapper to read genome sequences to provide personalized medical services in Germany. Conceivably the Topic-Mapper platform can be used to develop not only expert system apps but virtual personal assistant apps that tie together language processing and multitasking (watch out Siri!).
The ultimate goal is to have the Semantic Web and independently developed computer or device apps integrate to grow AI-level expert systems and virtual personal assistants that harness the vast information and connectivity power of the web. A good place to keep abreast of recent commercial Semantic Web developments is the SemanticWeb.com.
Intelligent Gaming
Gaming is one of the more prospective and lucrative areas for consumer AI. Machine learning has been applied in some games to adjust game playing tactics and strategy to the player, and to allow a player to train characters, such as in role-playing or action-adventure games (Halo 3, Forza Motorsport/Drivatar
and NEROgame were early adopters). There are drawbacks, including a worsening of player experience if the learning algorithms are limited, and this is connected to increased development cost and runtime computation/memory overhead. Game developers get around this by pre-programming in multiple levels of performance, providing modules, and allowing the user to change parameters during play.AI/machine learning is applied judiciously in cost-benefit areas, such as motion sensing (Kinect/Playstation Eye/Wii Remote Plus), situational assessment (pattern/object recognition), basic decision making/planning, etc.
Kinect in particular emphasizes controller-free gaming, using a bank of sensors (infrared camera, laser depth sensors, and microphone array), and capitalizing on basic gesture, facial and voice recognition software modules that are optimized for real-time performance (to a certain level). Microsoft Research Cambridge uses machine learning off-line to train and test a classifier using a very large database of pre-classified images, covering various body poses and types. The classifier is then able to more efficiently recognize basic on-line gestures and faces with less computational capacity and overhead. Microsofts release of the Kinect software development kit won accolades, and the pre-release hacks yielded some creative projects (see also The Kinect Effect). The 3D rendering capability has been particularly exploited for simultaneous localization and mapping (SLAM) applications.
The commercial release of Kinect for Windows is slated for early 2012, with hype that it will allow for hands-free computing, targeted toward such applications as surgery and teaching. Perhaps Kinect for Windows will be Microsofts Siri for the PC? One wonders what Apple (re: MacOS) is up to in this potentially very lucrative area. (The latest intel is that Apple/iTV and the next iPad release will incorporate gesture and speech recognition, the latter ala Siri.) No doubt that a virtual personal assistant for home/office/business that is able to recognize user gestures, body language, facial features, voices/audible nuances, has considerable potential, and is not just for gaming (though gaming is where it all started – Kinect for Xbox 360 has been one of the fastest selling consumer electronics devices).
Kinect has not escaped critical review – latency in motion recognition is one of the top issues. Sonys Playstation receives better reviews in some cases, as that system integrates accurate cues from the Move navigation controller and is not hands-free.
Noninvasive brain-machine interfaces (nBMIs) have also hit the gamer market in recent years, to mixed performance and reviews, perhaps due to the relative infancy of the technology, and perhaps due to the restrictions of interpreting brainwaves. The basic idea is a head-mounted system with sensors that measure electroencephalography (EEG) signals, and system software that interprets the signals to enable game control to some level. Neurosky (website) has produced several consumer gamer products, including Mindflex, in which players lift and move a ball through a maze, however independent critical reviews have questioned whether the toy measures actionable brainwaves or just randomly moves the ball, exploiting some sort of illusion of control. Neurosky also sells MindWave, a turnkey brainwave sensing headset based on the same biosensor (single dry electrode) as Mindflex, measuring brainwave impulses from the forehead from a position neuroscientists call FP1 with research grade precision, though some sources claim it also analyzes electrical activity produced by skeletal muscles as well (electromyography). Neurosky sells several games that test relaxation, meditation and attention, as well as concentration in completing gamer tasks. These have had mixed reviews similar to that of Mindflex, but hobbyists have found use in the headset for its ability to provide EEG band powers/wave patterns and raw EEG wave samples, that can be extracted to a microcontroller through a hack (read this decent review here). Competitor Emotiv EPOC (website) has received a variety of reviews, somewhat critical and somewhat complementary. That system uses an array of 14 EEG sensors, with multi-signal detection and analysis.
So are nBMIs really useful to gamers? My guess is yes, but like the research grade devices that have been successfully adapted to and used by paralyzed, locked-in patients for communicating through a cursor-keyboard system [10], the system requires extensive personalized tweaking and training, and relies on multi-signal, multi-modal detection and analysis (slow cortical potential or SCP brainwaves, mu waves, and/or the P300 potential). It seems we are a long way from using nBMIs for virtual reality, but as I have frequently argued, impeded progress just gives further impetus for continued basic research. Invasive BMIs will in all likelihood be required for greater functionality – I review those in detail in Part 4.
Machine learning and module pre-training can only improve gaming (and virtual personal assistant) products, though developers must start to move beyond what I call early generation AI algorithms that yield limited performance, and focus on next generation AI algorithms that are based more closely on human intelligence, cortical learning, vision and object recognition, natural language processing, and reasoning capability. These approaches are centered on how the modern neocortex learns (see cortical learning in the primer on machine learning) or more generally, deep learning. I review one very promising approach in Part 3: hierarchical temporal memory. Using predictive capability from hierarchical, inference-based algorithms may improve latency in games, one of the thornier problems.
Finally, a teaser. The strategy game of Go is considered by some to be a grand challenge of AI: the best Go programs cannot beat good human amateurs, yet the latest chess programs (e.g. Hydra) routinely beat chess grandmasters. Several prominent AI game developers are focused on Computer Go. There are basic differences separating Go from chess: brute force game tree search is much more difficult than chess – Go has a high branching factor of ~200 moves compared to chess at ~35 moves; and position evaluation is more complex – no intrinsic value of the stone and an irreducible winning criterion. The complexity of pattern matching/ranking and decision trees is significant.
The tease of Go appears to be matched well to the human brain architecture though: the number of possible games of Go far exceeds the number of atoms in the known universe, while the number of possible permutations and combinations of brain activity (brain states) exceeds the number of elementary particles in the known universe.
How Watson and Siri use NLP
Siri cant play Jeopardy!, and Watson cant take dictation. Watson cant talk to Siri
Siri
Siri employs a user interface linked to NLP/NSP
engines to process and recognize user voice commands, which are then used to
generate task actions, including answering simple questions. Siris natural speech processing (NSP) engine is reportedly
based on Nuance Communications Dragon
NaturallySpeaking (DNS),
automatic speech recognition (ASR) software that primarily focuses on
continuous speech dictation, but that also interfaces with computer and mobile
device e-mail and search engine apps. Apple licenses Nuances ASR service for
its iOS.
DNS and Siri speech-to-text ASR algorithms likely use statistical
models (e.g. hidden Markov models (HMMs); see a excellent review HERE) to recognize speech, which are robust against voice variation and
background noise. HMMs recognize speech by estimating the likelihood of each
phoneme at contiguous, small regions (frames) of the speech signal. Each word
in a vocabulary list is specified in terms of its component phonemes. A search
procedure is used to determine the sequence of phonemes with the highest
likelihood. This search is constrained to only look for phoneme sequences that
correspond to words in the vocabulary list, and the phoneme sequence with the
highest total likelihood is identified with the word that was spoken. Machine
learning (ML) pre-training of the recognition modules is applied using a corpus
of speech and text data to improve recognition speed and accuracy, while also
expanding vocabulary, before product release or upgrades. Recognition modules
may be optimized for phone/phoneme context-dependency to minimize processing at
the NLP level. ML algorithms and custom tools are included in DNS to allow
users to acoustically train DNS to a specific voice, and to improve accuracy
and vocabulary over time, automatically and through tool tuning. Siri does all of this automatically and adaptively over
time, improving recognition accuracy, but reportedly Siri
still has significant issues with certain accents and dialects.
Classification of voice accents is apparently still a thorny problem. DNS
claims to allow for dictation 3x faster than typing, at 99% accuracy, with the
ability to customize vocabulary, and reviewers generally have validated the
accuracy. Accuracy, speed and vocabulary metrics are not readily available for Siri (but could and should be methodically tested by an
outside source!).
After the
ASR/speech-to-text step, DNS and Siri diverge in
functionality. DNS is designed and optimized for continuous speech dictation,
and Siri is optimized to recognize and learn short
commands that map to multiple tasks it can accomplish within the iPhone/iOS ecosystem. Siri applies NLP
on translated speech-to-text words and sequence-of-words to recognize
actionable commands and phrases, with likely emphasis on the lexical level. As
users have found, this recognition has limits sourced to processing
deficiencies at all of the basic language levels (morphological, lexical,
syntactic, and most especially, semantic – see the NLP Primer for more background). To handle semantic
information content, Siri may employ what is called
semantic autocomplete, which is similar to the autocomplete function in
search engine boxes. The output of this process is parsed text, but may also
contain semantic information encoding (semantic completion), which is then
evaluated for intent and question, detecting user commands, actions and
questions. Siri transforms (summarizes) remotely
extracted web information and answers to questions into natural language text,
and then text-to-speech synthesized speech.
How much of Siris NLP is applied locally on the phone vs. on remote
servers is a good one. Those who have looked at reverse-engineering Siris protocols surmise that much of the ASR and NLP tasks are done on the server side, and
not locally on the phone. The reasons for this are many – but a top one
is that models for open-domain ASR/NLP systems tend to be large and
computationally intensive. Also, by handling much of the processing remotely,
it is easier for developers to improve those models (as measured by accuracy,
speed, vocabulary, etc.). Many developers agree that more of this processing
will be pushed locally to the client side as technologies improve, and this is
certainly possible with specialized hardware and embedded software (FPGAs,
ASICs, etc.). Newer rival Evi has some ASR/NLP
advantages over Siri, namely in terms of being able to
better recognize phrases semantically and supply more relevant answers to
questions, but the same discussion on where the NLP takes place (local
client/remote server) applies. NovaSearch (reviewed
earlier under Siri) is a phonetic speech recognition
engine that operates on phonemes rather than translated text, and may offer a complementary mode of
search and multitasking capability to Siri or Evi, with more efficient local embedded processing, cutting
down on data bandwidth.
Finally, the speech synthesis
(text-to-speech) process in Siri (based on Nuances VoiceOver) and other similar devices must not be
ignored. As many users can attest, synthesizers are woefully inadequate at
producing a normal sounding human voice. Prosodic and emotional content is
either largely or completely missing. Phoneme content is challenged –
pronunciations are stilted and sometimes completely incorrect, such as when
contextual meaning is ignored. Disambiguating homographs is a
tough problem, and is addressed by integrating heuristics with statistical
models (e.g. hidden Markov models).
On a mobile device the synthesis software/hardware is constrained and
limited, but even Nuances Vocalizer and AT&T Lab's Natural Voices software miss the mark, calling for new
technological approaches to natural speech synthesis. (Type in My latest
project is to learn how to better project my voice into the text field of the
demo – as of January 2012, Vocalizer could not disambiguate project,
and neither sounded natural.)
Watson
As stated in [2]: Watson/DeepQA is a
massively parallel probabilistic evidence-based architecture. For the Jeopardy Challenge,
we use more than 100 different techniques for analyzing natural language,
identifying sources, finding and generating hypotheses, finding and scoring
evidence, and merging and ranking hypotheses. What is far more important than
any particular technique we use is how we combine them in DeepQA
such that over-lapping approaches can bring their strengths to bear and
contribute to improvements in accuracy, confidence, or speed
During question
analysis the system attempts to understand what the question is asking and
performs the initial analyses that determine how the question will be processed
by the rest of the system. The DeepQA approach
encourages a mixture of experts at this stage, and in the Watson system we
produce shallow parses, deep parses, logical forms, semantic role labels, coreference, relations, named entities, and so on.
Watson relies [2] on
analyzing questions by extracting the lexical answer type (LAT) when present. LAT
is defined to be a word in the clue that indicates the type of the answer, independent
of assigning semantics to that word. A simple example given is the following
clue where the LAT is the string maneuver:
Category: Oooh....Chess
Clue:
Invented in the 1500s to speed up the game, this maneuver involves two pieces of
the same color.
Answer:
Castling
When an explicit LAT
is not present (claimed for ~12% of the universe of clues analyzed), Watson
uses contextual inference, such as is done in the following example:
Category:
Decorating
Clue: Though
it sounds harsh, its just embroidery, often in a
floral pattern, done with yarn on cotton cloth.
Answer: Crewel
IBM uses these examples to illustrate why their approach to NLP and QA is geared toward analyzing unstructured data and assigning statistical scoring using collected evidence, as opposed to getting the answer from curated data (Wolfram|Alpha answers questions based on curated data). Though they admit that task-specific type systems or manually curated data would have some impact if applied to non-explicit LAT cases, it would be focused on a small percentage of cases. Our clear technical bias for both business and scientific motivations is to create general-purpose, reusable natural language processing (NLP) and knowledge representation and reasoning (KRR) technology that can exploit as-is natural language resources and as-is structured knowledge rather than to curate task-specific knowledge resources.
Following this approach, Watson uses IBMs Unstructured Information Management Architecture (UIMI). The UIMI software components analyze unstructured text and produce annotations or assertions about the text, in short, it preprocesses a corpus (see the NLP Primer for more background), which is then used along with a variety of sources for further QA analysis. No doubt semi-supervised machine learning techniques are key to this process, in fact IBM quotes the use of a few specific techniques used for NLP scoring. Watson has evolved over time and the number of components in the system has reached into the hundreds [2].
References
and Endnotes:
[1] IBM Research Explains What Makes Watson Tick, B. Parr, Mashable, Feb. 2011.
[2] Building Watson: An Overview of the DeepQA Project, D. Ferrucci, et al., AI Magazine, Fall 2010.
[3] Watson Doesnt Know it Won on Jeopardy! J. Searle, Wall Street Journal, Feb. 2011.
[4] With Siri, Apple Could Eventually Build A Real AI, J. Stokes, Wired Cloudline, Oct. 2011.
[6] Wolfram|Alpha: Searching for Truth, R. Rucker, h+ Online, Apr. 2009.
[7] The Semantic Web, T. Berners-Lee, J. Hendler and O. Lassila, Scientific American, May 17, 2001.
[8] See W3C Semantic Web Activity and working group links contained therein. This site is updated regularly with standards, specifications, publications, presentations, case studies, and an activity weblog.
[9] Dynamically Linked Web Data – The Next Internet Revolution, S. Lomatch, Apr. 2009.
[10] Thinking Out Loud, N. Neumann and N. Birbaumer, Sci. Am. Mind, vol 14 (5), Dec. 2004. (Also reprinted in The Best of the Brain, ed. F. Bloom, Sci Am. Books, 2007.)